mysql索引
如何建索引
- 索引并非越多越好,占空间、影响insert、delete、update性能
- 避免对经常更新的表做很多索引,而且索引中的列应尽可能少;对于经常查询的字段创建索引
- 数据量小的表尽量不用索引
- 在不同值多的列上建立索引,如只有男女两个值,无需索引
- 在频繁排序或者分组的列上建立索引
监测慢sql
打开慢查询日志
slow_query_log=1
慢查询日志存储路径
slow_query_log_file=/var/log/mysql/log-slow-queries.log
SQL执行时间大于3秒,则记录日志
long_query_time=3
索引分类
逻辑角度:主键索引(特殊的唯一索引,不允许空值)、普通索引、联合索引、唯一索引。
数据结构角度:B+树索引、哈希索引。。。
物理存储角度:聚簇索引、非聚簇索引。
回表查询、索引覆盖
如果通过读取索引仅能得到想要的数据,就不需要回表读取行了,一个索引包含了满足查询结果的数据就叫索引覆盖。
一个列,数据都是唯一的,需要建一个索引,建唯一索引还是普通索引
唯一索引。(即使应用层做了很完善的校验机制,只要没有唯一索引,根据墨菲定律,必然有脏数据发生)
为什么唯一索引插入速度比普通索引慢?
唯一索引需要先将数据读取到内存里,再在内存里进行数据的唯一校验。
为什么唯一索引查询速度比普通索引快?
因为普通索引查询到满足调剂的记录之后,还要接着判断;唯一索引查到第一条记录直接返回。
mysql索引结构?
B+树。AVL树和红黑树是存储在内存里才会使用的数据结构。B树有两个特点:树内存储数据、叶子结点无链表。B树在提高磁盘IO性能的同时没有解决元素遍历效率低的问题。还有就是范围查询。B+树优点之一:不用多读取无用结点的数据,只有索引。
联合索引?
注:遇到范围查询(> < between like)停止匹配。
如(a,b)建立索引
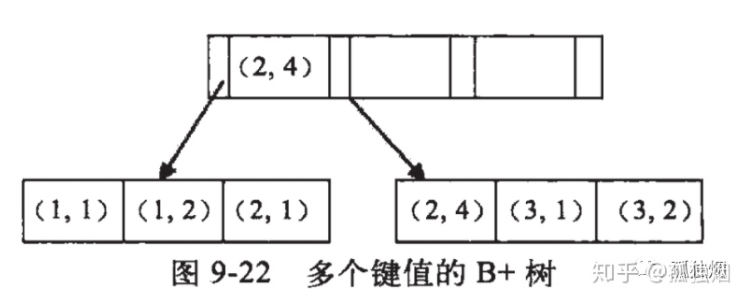
全局来看,b是无序的,索引直接b=2没法利用索引,但是局部看,a确定的时候,b是有序的,如果a是一个范围,b就不是有序的,用不了,所以用到范围查询就会停止匹配。
a = 1
a = 1 and b = 2
b = 2 and a = 1 #也可以,优化器会自动调整顺序
b = 2 #不行,匹配不到索引
如(a,b,c,d)建立索引
a = 1 and b = 2 and c > 3 and d = 4
# a,b,c能用到索引,d用不到,因为遇到了范围查询
联合索引例子
1
SELECT *FROM table WHERE a = 1 and b = 2 and c=3;
如何建立索引?这个条件的话(a,b,c)和(c,b,a)和(b,a,c)等都可以,重要的是将区分度高的字段放前面,区分度低的放后面(如性别,状态)
2
SELECT * FROM table WHERE a>1 and b=2;
应该(b,a)索引,因为最左匹配原则遇到范围查询会停止匹配,至于语句中where后面的顺序,优化器会调整以便用上索引。
or索引失效
指的是查询条件包含了非索引字段和索引字段,会导致索引字段走不了。
mysql高可用方案
高可用,考虑的是如果数据库发生宕机,能尽可能减少停机时间,保证业务不会因为数据库故障中断,用作备份或者只读副本的非节点数据应和主节点数据实时或保持最终一致,业务发生数据库切换时,前后内容应一致。
- 主从同步
三大范式
- 字段具有原子性,不可再分(字段单一职责)
- 每行被唯一区分,主键(都要依赖主键)
- 一个表不能包含其他表的已存在的非主键信息
自增主键
mysql8,将自增值的变更记录在了redo log,重启的时候可以依靠redo log恢复重启之前的值。
不连续,如两个事务同时插入,其中一个回滚了,id不连续,牺牲了主键的连续性来支持并发数据插入。
自增主键用完了?把int类型改为BigInt类型。但是这个在建表前就应该考虑设置为bigint,或者分库分表。
自增主键、uuid:主键的值是顺序的,所以 InnoDB 把每一条记录都存储在一条记录的后面。uuid 相对顺序的自增 id 来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以 innodb 无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间。
分库分表
单数据库能支撑的并发量优先,拆成多个库可以使服务之间不用竞争。
分表:水平拆分和垂直拆分。
如简单点哈希对用户id然后取模,找到对应的库,进行存储和读取。但是这样动态增加或者删除结点就会出现问题,解决:一致性哈希。
不对服务器数量取模,对2^32取模,将哈希值空间组织成一个虚拟的圆环,如有4台服务器,根据它们的ip或者主机名进行哈希计算,然后对2^32取模。根据用户ip也哈希计算,确定数据在换上的位置,遇到的第一台服务器就是定位到的服务器。
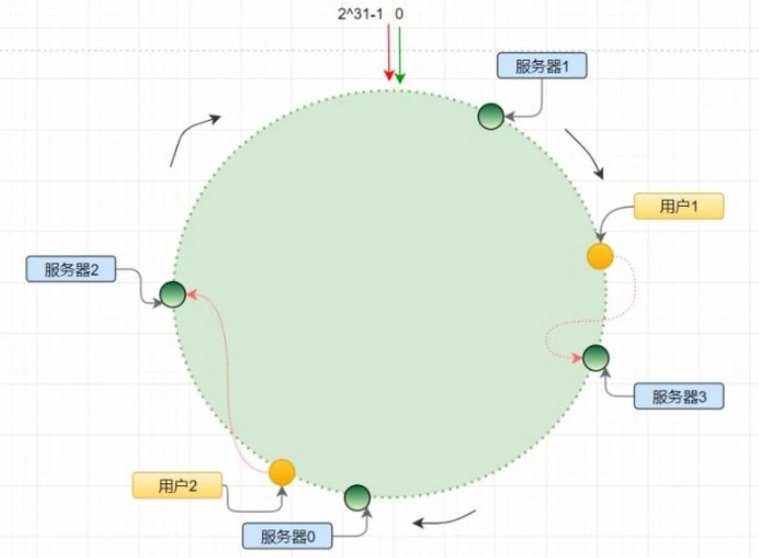
新增节点:通过一致性哈希算法计算在哈希环的位置,数据的迁移达到最小。数据倾斜问题:多进行几次哈希,当虚拟节点。