java多线程的一些question
创建线程的三种方式的对比?
继承Thread重写run方法
线程类已经继承了Thread类,所以不能再继承其他父类。
public class ThreadDemo extends Thread{
int i = 0;
@Override
public void run() {
for(;i<100;i++) {
System.out.println(getName()+" "+i);
}
}
public static void main(String[] args) {
for(int j=0;j<100;j++) {
System.out.println(Thread.currentThread().getName()+": "+j);
if(j==50) {
new ThreadDemo().start();
new ThreadDemo().start();
}
}
}
}
1)采用实现Runnable. Callable接口的方式创建多线程。
优势是:
线程类只是实现了Runnable接口或Callable接口,还可以继承其他类。
在这种方式下,多个线程可以共享同一个target对象,所以非常适合多个相同线程来处理同一份资源的情况,从而可以将CPU. 代码和数据分开,形成清晰的模型,较好地体现了面向对象的思想。
劣势是:
编程稍微复杂,如果要访问当前线程,则必须使用Thread.currentThread()方法。
实现Runnable接口
public class ThreadDemo implements Runnable{
int i = 0;
@Override
public void run() {
for(;i<100;i++) {
System.out.println(Thread.currentThread().getName()+" "+i);
}
}
public static void main(String[] args) {
for(int j=0;j<100;j++) {
System.out.println(Thread.currentThread().getName()+": "+j);
if(j==50) {
ThreadDemo demo = new ThreadDemo();
new Thread(demo,"线程1").start();
new Thread(demo,"线程2").start();
}
}
}
}
实现Callable接口
- Callable的任务执行后可返回值,而Runnable的任务是不能返回值的。
public class ThreadDemo implements Callable<Integer> {
int i = 0;
@Override
public Integer call() throws Exception {
for(;i<100;i++) {
System.out.println(Thread.currentThread().getName()+" "+i);
}
return i;
}
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadDemo demo = new ThreadDemo();
FutureTask<Integer> futureTask = new FutureTask<>(demo);
for(int j=0;j<100;j++) {
System.out.println(Thread.currentThread().getName()+": "+j);
if(j==50) {
new Thread(futureTask,"线程1").start();
}
}
System.out.println("子线程的返回值:" + futureTask.get());
}
}
Runnable VS Callable
- Callable仅在 Java 1.5 中引入,目的就是为了来处理Runnable不支持的用例。Callable 接口可以返回结果或抛出检查异常
- Runnable 接口不会返回结果或抛出检查异常,
- 如果任务不需要返回结果或抛出异常推荐使用 Runnable接口,这样代码看起来会更加简洁
- 工具类 Executors 可以实现 Runnable 对象和 Callable 对象之间的相互转换。(Executors.callable(Runnable task)或 Executors.callable(Runnable task,Object resule))
sleep() 方法和 wait() 方法区别和共同点?
区别:
- sleep方法:是Thread类的静态方法,当前线程将睡眠n毫秒,线程进入阻塞状态。当睡眠时间到了,会解除阻塞,进入可运行状态,等待CPU的到来。睡眠不释放锁(如果有的话)。
- wait方法:是Object的方法,必须与synchronized关键字一起使用,线程进入阻塞状态,当notify或者notifyall被调用后,会解除阻塞。但是,只有重新占用互斥锁之后才会进入可运行状态。睡眠时,会释放互斥锁。
- sleep 方法没有释放锁,而 wait 方法释放了锁 。
- sleep 通常被用于暂停执行Wait 通常被用于线程间交互/通信
- sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法
相同:都可以暂停线程的执行。
start()
直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
Thread.yield()
Yield方法可以暂停当前正在执行的线程对象,让其它有相同优先级的线程执行。它是一个静态方法而且只保证当前线程放弃CPU占用而不能保证使其它线程一定能占用CPU,执行yield()的线程有可能在进入到暂停状态后马上又被执行。
volatile
保证对所有线程的可见性、避免了指令重排优化。
线程状态
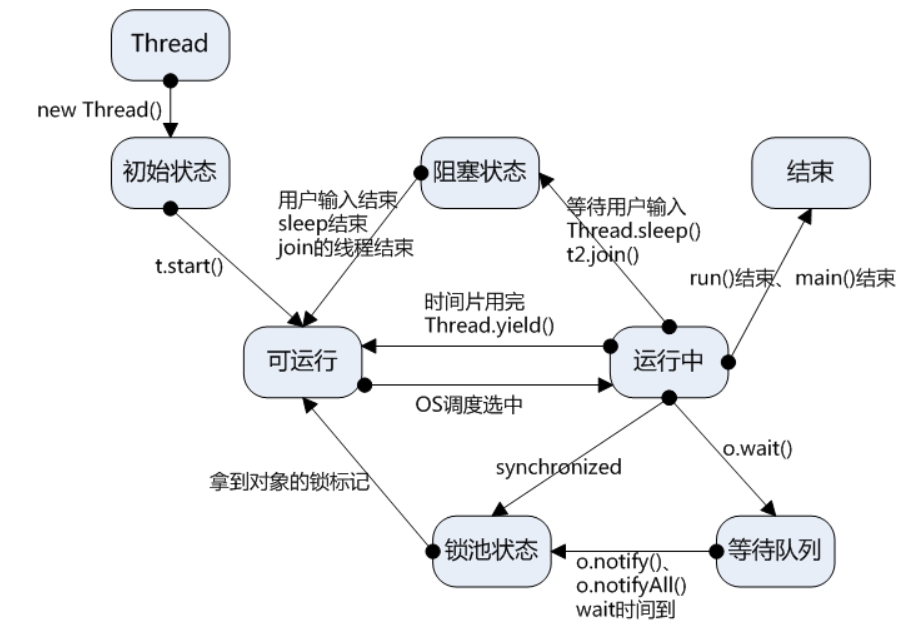
线程阻塞的三种情况
- o.wait() -> 等待队列
- lock -> 锁池
- sleep/join
当 sleep() 状态超时,join() 等待线程终止或超时. 或者 I/O 处理完毕时,线程重新转入可运行状态(RUNNABLE)
守护线程
运行在后台的一种特殊进程。如垃圾回收线程。
Fork/Join框架
Fork/Join框架是Java7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
Fork/Join框架需要理解两个点,「分而治之」和「工作窃取算法」。
CAS缺陷
ABA问题:
public class ThreadDemo { private static AtomicInteger index = new AtomicInteger(10); public static void main(String[] args) { new Thread(()-> { index.compareAndSet(10,11); index.compareAndSet(11,10); System.out.println(Thread.currentThread().getName()+" :10->11->10"); },"new Thread").start(); new Thread(()->{ try { TimeUnit.SECONDS.sleep(2); boolean isSuccess = index.compareAndSet(10,12); System.out.println(isSuccess); } catch (InterruptedException e) { e.printStackTrace(); } }).start(); // new Thread :10->11->10 // true } }如何解决?
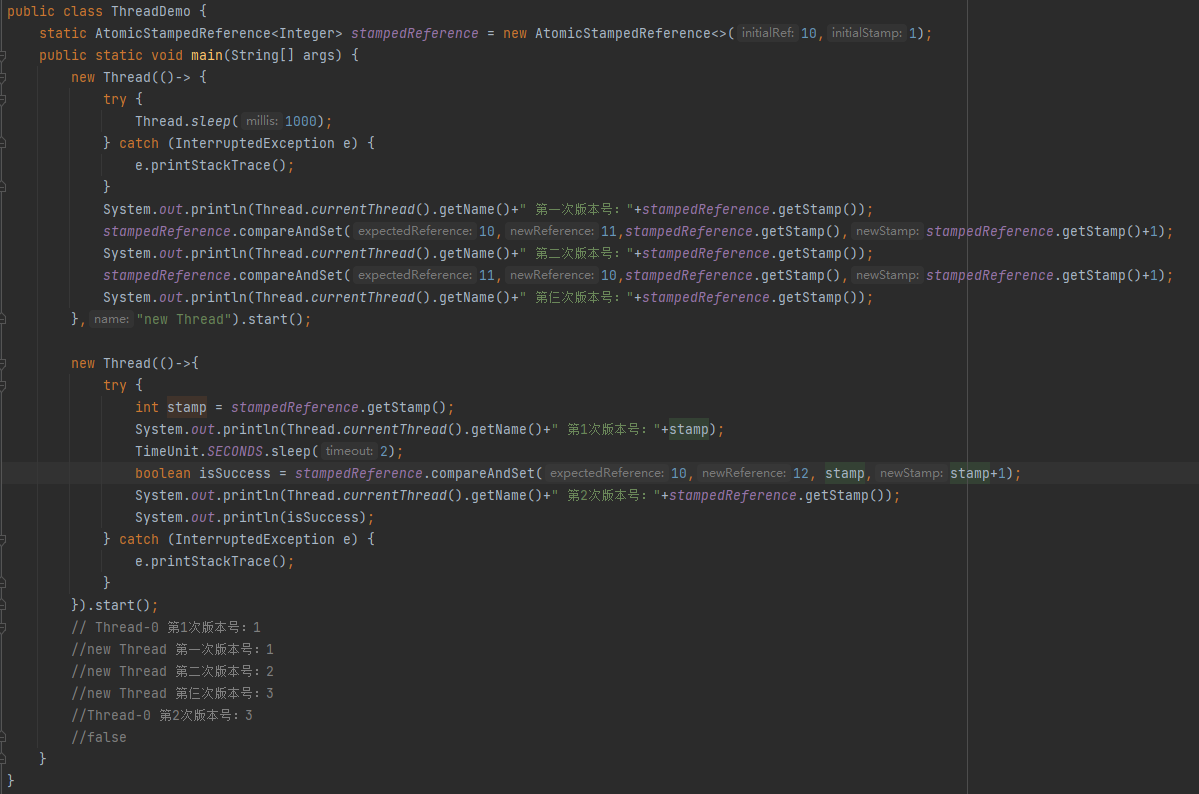
循环长时间开销
自旋CAS,如果一直循环执行,一直不成功,会给CPU带来非常大的执行开销。很多时候,CAS思想体现,是有个自旋次数的,就是为了避开这个耗时问题~
只保证一个变量的原子操作
- 互斥锁
- 将多个变量封装为对象,用
AtomicReference保证原子性
synchronized 和 Lock 有什么区别?
- synchronized 可以给类. 方法. 代码块加锁;而 lock 只能给代码块加锁。
- synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁;而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
- 通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
synchronized 和 ReentrantLock
synchronized依赖于JVM,进行了很多优化,ReentrantLock是JDK层面的。要lock和unlock配合。
ReentrantLock增加了一些功能:可指定公平锁(synchronized只能是非公平锁)、等待可中断、在使用notify()/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知”
synchronized使用方法
修饰代码块:
public void run() {
// 锁住了该对象,试图访问该对象的线程被阻塞
synchronized(this) {
// do something
}
}
修饰某个对象
/**
* 账户操作类
*/
class AccountOperator implements Runnable{
private Account account;
public void run() {
synchronized (account) {
...
}
}
}
修饰一个方法:
public synchronized void run() {
...
}
synchronized关键字不能被继承
修饰静态方法:
public synchronized static void method() {
// todo
}
synchronized修饰的静态方法锁定的是这个类的所有对象
作用于类:
synchronized作用于一个类T时,是给这个类T加锁,T的所有对象用的是同一把锁。
/**
* 同步线程
*/
class SyncThread implements Runnable {
private static int count;
public static void method() {
synchronized(SyncThread.class) {
...
}
}
}
synchronized 底层实现原理
synchronized 同步代码块的实现是通过 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权。
其内部包含一个计数器,当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
synchronized 锁优化
32 位 HotSpot 虚拟机中 Mark Word 在不同状态下存储的信息:
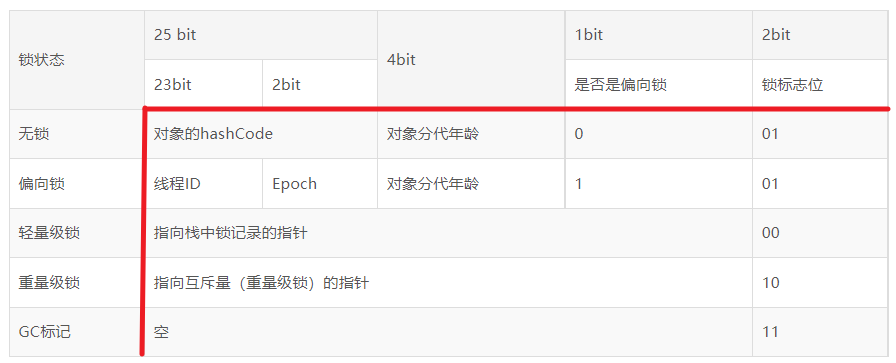
锁膨胀:无锁 - 偏向锁 - 轻量级锁 - 重量级锁,膨胀方向不可逆。
初始状态:无锁,偏向标志位0,锁标志01。
偏向锁
为了减少同一线程获取锁的代价。在大多数情况下,锁不存在多线程竞争,总是由同一线程多次获得,那么此时就是偏向锁。如果一个线程获得了锁,那么锁就进入偏向模式,此时Mark Word的结构也就变为偏向锁结构,当该线程再次请求锁时,无需再做任何同步操作,即获取锁的过程只需要检查Mark Word的锁标记位为偏向锁以及当前线程ID等于Mark Word的ThreadID即可,这样就省去了大量有关锁申请的操作。
轻量级锁
轻量级锁是由偏向锁升级而来,当存在第二个线程申请同一个锁对象时,偏向锁就会立即升级为轻量级锁。注意这里的第二个线程只是申请锁,不存在两个线程同时竞争锁,可以是一前一后地交替执行同步块。
建立锁对象:在加锁前,虚拟机需要在当前线程的栈帧中建立锁记录(Lock Record)的空间。Lock Record 中包含一个 _displaced_header 属性,用于存储锁对象的 Mark Word 的拷贝。
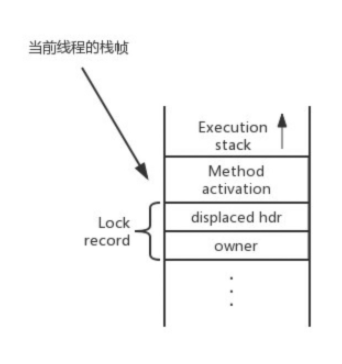
将锁对象的 Mark Word 复制到锁记录中,这个复制过来的记录叫做 Displaced Mark Word。具体来讲,是将 mark word 放到锁记录的 _displaced_header 属性中。
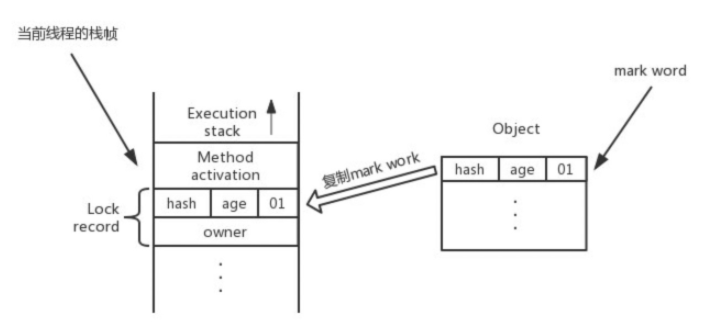
虚拟机使用 CAS 操作尝试将锁对象的 Mark Word 更新为指向锁记录的指针。如果更新成功,这个线程就获得了该对象的锁。
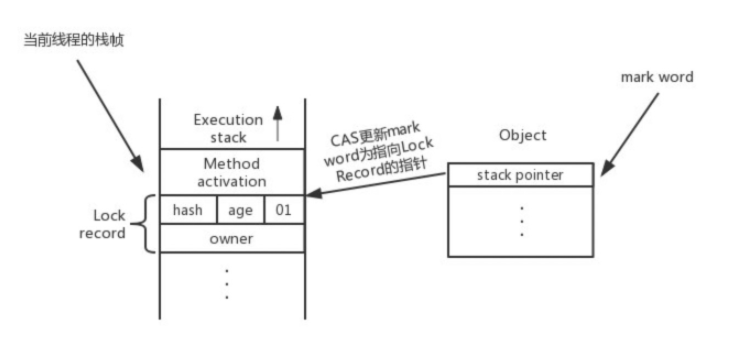
有锁状态下,如果是当前线程持有的轻量级锁,则说明是重入,不需要争抢锁。否则,说明有多个线程竞争,轻量级锁需要升级为重量级锁。
解锁的时候换回mark word

重量级锁
重量级锁是由轻量级锁升级而来,当同一时间有多个线程竞争锁时,锁就会被升级成重量级锁,此时其申请锁带来的开销也就变大。重量级锁一般使用场景会在追求吞吐量,同步块或者同步方法执行时间较长的场景。
synchronized 非公平锁
1)当持有锁的线程释放锁时,该线程会执行以下两个重要操作:
- 先将锁的持有者 owner 属性赋值为 null
- 唤醒等待链表中的一个线程(假定继承者)。
在1和2之间,如果有其他线程刚好在尝试获取锁(例如自旋),则可以马上获取到锁。
2)当线程尝试获取锁失败,进入阻塞时,放入链表的顺序,和最终被唤醒的顺序是不一致的,也就是说你先进入链表,不代表你就会先被唤醒(如可能被自旋锁插队)。
锁消除
消除锁是虚拟机另外一种锁的优化,这种优化更彻底,在JIT编译时,对运行上下文进行扫描,去除不可能存在竞争的锁。
锁粗化
锁粗化是虚拟机对另一种极端情况的优化处理,通过扩大锁的范围,避免反复加锁和释放锁。比如下面method3经过锁粗化优化之后就和method4执行效率一样了。
synchronized 锁能降级吗?
重量级锁降级发生于 STW (stop the world) 阶段,降级对象为仅仅能被 VMThread 访问而没有其他 JavaThread 访问的对象。被锁的对象都被垃圾回收了有没有锁还有啥关系?因此基本认为锁不可降级。
ThreadLocal
ThreadLocal,即线程本地变量。如果你创建了一个ThreadLocal变量,那么访问这个变量的每个线程都会有这个变量的一个本地拷贝,多个线程操作这个变量的时候,实际是操作自己本地内存里面的变量,从而起到线程隔离的作用,避免了线程安全问题。
//创建一个ThreadLocal变量
static ThreadLocal<String> localVariable = new ThreadLocal<>();
ThreadLocal的应用场景有
- 数据库连接池
- 会话管理中使用
原理
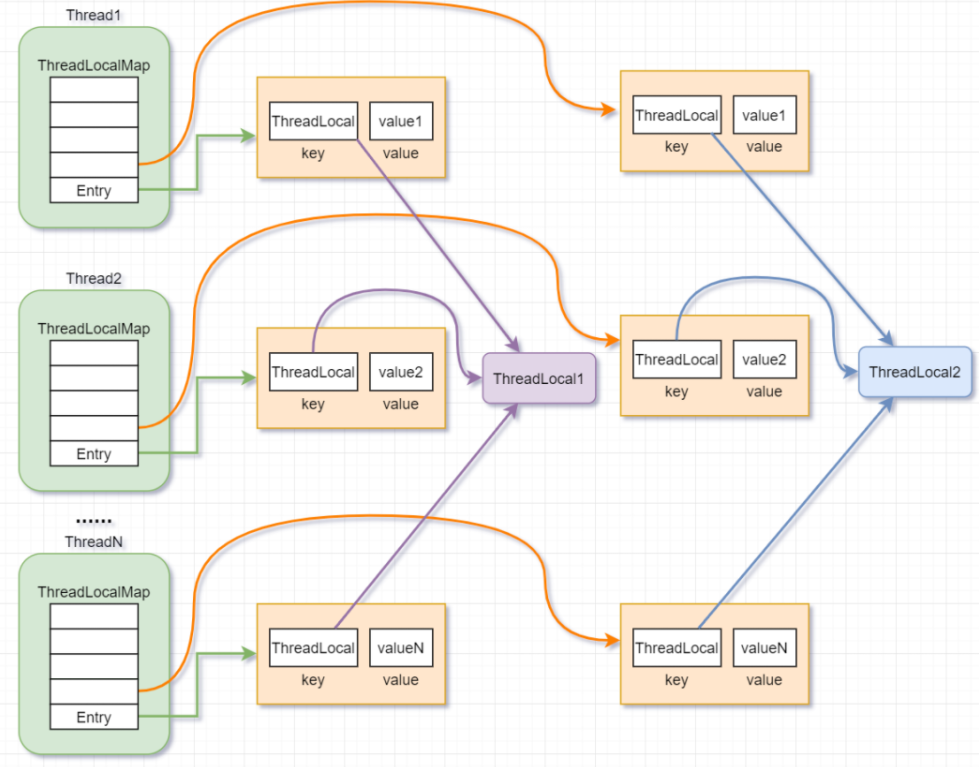
- Thread类有一个类型为ThreadLocal.ThreadLocalMap的实例变量threadLocals,即每个线程都有一个属于自己的ThreadLocalMap。
- ThreadLocalMap内部维护着Entry数组,每个Entry代表一个完整的对象,key是ThreadLocal本身,value是ThreadLocal的泛型值。
- 每个线程在往ThreadLocal里设置值的时候,都是往自己的ThreadLocalMap里存,读也是以某个ThreadLocal作为引用,在自己的map里找对应的key,从而实现了线程隔离。
内存泄露问题
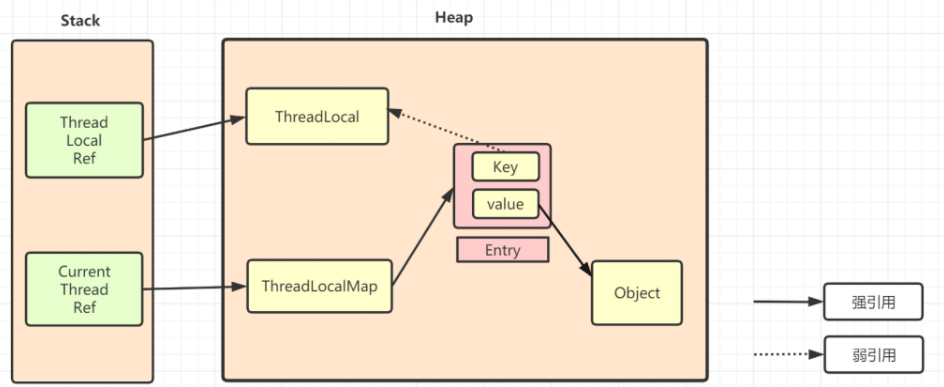
ThreadLocalMap中使用的 key 为 ThreadLocal 的弱引用
弱引用:只要垃圾回收机制一运行,不管JVM的内存空间是否充足,都会回收该对象占用的内存。
弱引用比较容易被回收。因此,如果ThreadLocal(ThreadLocalMap的Key)被垃圾回收器回收了,但是因为ThreadLocalMap生命周期和Thread是一样的,它这时候如果不被回收,就会出现这种情况:ThreadLocalMap的key没了,value还在,这就会造成了内存泄漏问题。
key弱引用并不是导致内存泄漏的原因,而是因为ThreadLocalMap的生命周期与当前线程一样长,并且没有手动删除对应value。
如何「解决内存泄漏问题」?使用完ThreadLocal后,及时调用remove()方法释放内存空间。
在ThreadLocal中,进行get,set操作的时候会清除Map里所有key为null的value。
线程池
原因
使用线程池的好处:
- 降低资源消耗。 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的可管理性。 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
execute()方法和submit()方法的区别
execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;- submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功