Java多线程volatile、ThreadLocal、线程池、atomic
volatile
CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。
volatile指示 JVM ,这个变量是共享不稳定的,每次使用都从内存中读取。
并发:
原子性(synchronized)、可见性(volatile,修改后其他线程可以立刻看到最新值)、有序性(volatile禁止指令重排序)。
synchronized 关键字和 volatile 关键字是两个互补的存在,而不是对立的存在!
volatile关键字是线程同步的轻量级实现,所以volatile性能肯定比synchronized关键字要好 。但是volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块 。volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。volatile关键字主要用于解决变量在多个线程之间的可见性,而synchronized关键字解决的是多个线程之间访问资源的同步性。
ThreadLocal
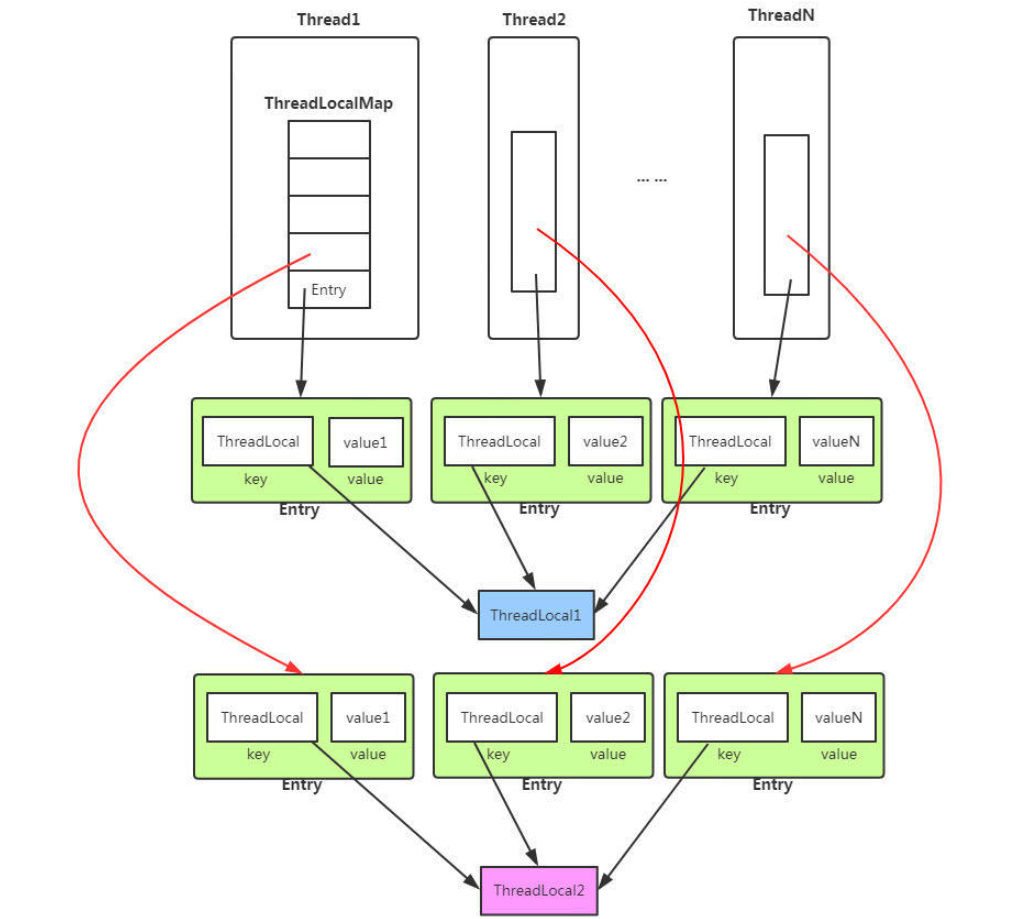
每个线程的专属本地变量,每个线程绑定自己的值。
每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为 key ,Object 对象为 value 的键值对。
如例:
package ThreadLocal;
import java.text.SimpleDateFormat;
import java.util.Random;
public class ThreadLocalExample implements Runnable{
private static final ThreadLocal<SimpleDateFormat> formatter = ThreadLocal.withInitial(()->new SimpleDateFormat("yyyyMMdd HHmm"));
public static void main(String[] args) throws InterruptedException {
ThreadLocalExample obj = new ThreadLocalExample();
for(int i=0;i<10;i++) {
Thread t = new Thread(obj,""+i);
Thread.sleep(new Random().nextInt(1000));
t.start();
}
}
@Override
public void run() {
System.out.println("Thread name="+Thread.currentThread().getName()+" default formatter = "+formatter.get().toPattern());
try {
Thread.sleep(new Random().nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
formatter.set(new SimpleDateFormat());
System.out.println("Thread name="+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
}
}
ThreadLocalMap 中使用的 key 为 ThreadLocal 的弱引用,而 value 是强引用。所以,如果 ThreadLocal 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,ThreadLocalMap 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 set()、get()、remove() 方法的时候,会清理掉 key 为 null 的记录。使用完 ThreadLocal方法后,最好手动调用remove()方法。
弱引用
Java 中存在四种引用,它们由强到弱依次是:强引用、软引用、弱引用、虚引用。下面我们简单介绍下除弱引用外的其他三种引用:
- 强引用(Strong Reference):通常我们通过new来创建一个新对象时返回的引用就是一个强引用,若一个对象通过一系列强引用可到达,它就是强可达的(strongly reachable),那么它就不被回收。
- 软引用(Soft Reference):软引用和弱引用的区别在于,若一个对象是弱引用可达,无论当前内存是否充足它都会被回收,而软引用可达的对象在内存不充足时才会被回收,因此软引用要比弱引用“强”一些。
- 弱引用对象的存在不会阻止它所指向的对象变被垃圾回收器回收。弱引用最常见的用途是实现规范映射(canonicalizing mappings,比如哈希表)。假设垃圾收集器在某个时间点决定一个对象是**弱可达的(weakly reachable)(也就是说当前指向它的全都是弱引用),这时垃圾收集器会清除所有指向该对象的弱引用,然后垃圾收集器会把这个弱可达对象标记为可终结(finalizable)的,这样它们随后就会被回收。与此同时或稍后,垃圾收集器会把那些刚清除的弱引用放入创建弱引用对象时所登记到的引用队列(Reference Queue)**中。
- 虚引用(Phantom Reference):虚引用是Java中最弱的引用,那么它弱到什么程度呢?它是如此脆弱以至于我们通过虚引用甚至无法获取到被引用的对象,虚引用存在的唯一作用就是当它指向的对象被回收后,虚引用本身会被加入到引用队列中,用作记录它指向的对象已被销毁。
线程池
uuid: UUID 含义是通用唯一识别码 (Universally Unique Identifier),这是一个软件建构的标准。UUID由以下几部分的组合:
当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。
时钟序列。
全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
UUID 的唯一缺陷在于生成的结果串会比较长。关于UUID这个标准使用最普遍的是微软的GUID(Globals Unique Identifiers)。标准的UUID格式为:xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx (8-4-4-4-12)。
例子:
public class ThreadPoolExample {
//创建一个不限制线程个数的线程池
// private static ExecutorService exec = Executors.newCachedThreadPool(new ThreadFactory() {
// @Override
// public Thread newThread(Runnable r) {
// Thread t = new Thread(r);
// t.setName("worker-thread-"+ UUID.randomUUID().toString());
// return t;
// }
// });
// lambda形式
private static final ExecutorService exec2 = Executors.newCachedThreadPool(r -> {
Thread t = new Thread(r);
t.setName("worker-thread-"+ UUID.randomUUID().toString());
return t;
});
private static final ExecutorService exec = Executors.newFixedThreadPool(5,r -> {
Thread t = new Thread(r);
t.setName("worker-thread-"+ UUID.randomUUID().toString());
return t;
});
public static void main(String[] args) {
for(int i=0;i<10;i++) {
exec.submit(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
}
CachedThreadPool 主要被应用在响应时间要求高、数据量可控的场景,由于其不限制创建线程的个数,故若数据量不可控,会造成程序 OOM。
FixedThreadPool 主要被应用在线程资源有限,数据量较小或不可控场景。
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
// ThreadPoolExecutor 构造函数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime, // keepAliveTime:超过corePoolSize数的空闲线程在被销毁之前等待新任务到达的最长时间
TimeUnit unit,
BlockingQueue<Runnable> workQueue, // 默认无限大
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
ThreadPoolExecutor 3 个最重要的参数:
corePoolSize: 核心线程数线程数定义了最小可以同时运行的线程数量。maximumPoolSize: 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。workQueue: 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数:
keepAliveTime: 当线程池中的线程数量大于corePoolSize的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了keepAliveTime才会被回收销毁;unit:keepAliveTime参数的时间单位。threadFactory: executor 创建新线程的时候会用到。handler: 饱和策略。
任务队列默认无限大,在我们处理的数据量较大或者并发量很大时,应避免直接使用 Executors 提供的 FixedThreadPool。
但是由于 ThreadPoolExecutor 在等待队列满时,会拒绝任务插入并直接丢弃,所以针对于不可以丢弃的任务,就不能简单的采用这种方式。可以变更拒绝策略。最简单的方式就是通过增加一个拒绝策略,该策略中做的便是对等待队列进行阻塞写入,也就实现了线程池提交任务的阻塞等待。
public class ThreadLocalExample{
private static ExecutorService exec = new ThreadPoolExecutor(10,10,0L, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100),r -> {
Thread t = new Thread(r);
t.setName("worker-thread-" + UUID.randomUUID().toString());
return t;
},(r,executor)->{
if(!executor.isShutdown()) {
try {
//阻塞等待put操作
System.err.println("waiting queue is full, putting...");
executor.getQueue().put(r);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
private static AtomicInteger at = new AtomicInteger(0);
public static void main(String[] args) {
while (true) {
exec.submit(() -> {
System.err.println("Worker" + at.getAndIncrement() + " start.");
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.err.println("Worker end.");
});
}
}
}
Atomic原子类
JUC (java.util.concurrency) 4大原子类:
基本类型
使用原子的方式更新基本类型
AtomicInteger:整形原子类AtomicLong:长整型原子类AtomicBoolean:布尔型原子类
数组类型
使用原子的方式更新数组里的某个元素
AtomicIntegerArray:整形数组原子类AtomicLongArray:长整形数组原子类AtomicReferenceArray:引用类型数组原子类
引用类型
AtomicReference:引用类型原子类AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。AtomicMarkableReference:原子更新带有标记位的引用类型
对象的属性修改类型
AtomicIntegerFieldUpdater:原子更新整形字段的更新器AtomicLongFieldUpdater:原子更新长整形字段的更新器AtomicReferenceFieldUpdater:原子更新引用类型字段的更新器
AtomicInteger的本质:自旋锁+CAS原子操作
乐观锁,性能较强,利用CPU自身的特性保证原子性,即CPU的指令集封装compare and swap两个操作为一个指令来保证原子性。适合读多写少模式。
但是缺点明显:自旋,消耗 CPU 性能,所以写的操作较多推荐sync。仅适合简单的运算,否则会产生ABA问题,自旋的时候,别的线程可能更改 value,然后又改回来,此时需要加版本号解决,JDK提供了AtomicStampedReference 和 AtomicMarkableReference 解决ABA问题,提供基本数据类型和引用数据类型版本号支持。
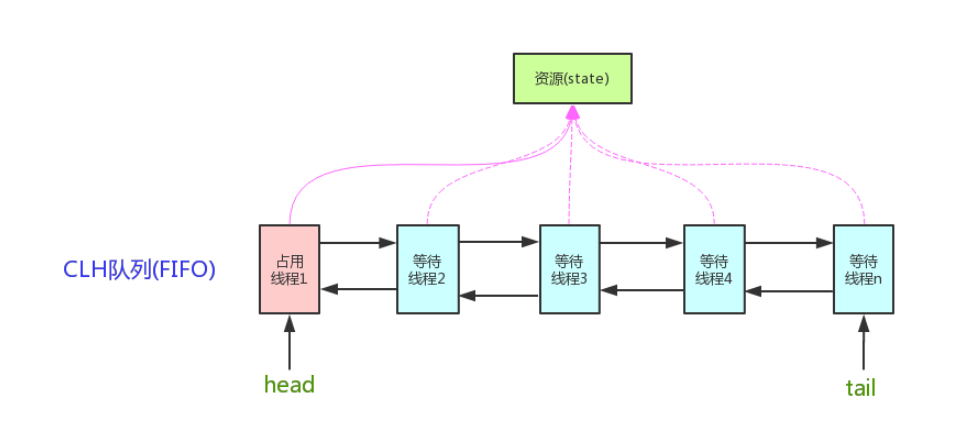
AQS
全称为AbstractQueuedSynchronizer,抽象队列同步器。
ReentrantLock这种东西只是一个外层的API,内核中的锁机制实现都是依赖AQS组件的。它包含了state变量、加锁线程、等待队列等并发中的核心组件。