回顾一下MySQL的一些常规操作
OK,又是好久没写SQL了,回顾一下。
牛客链接。
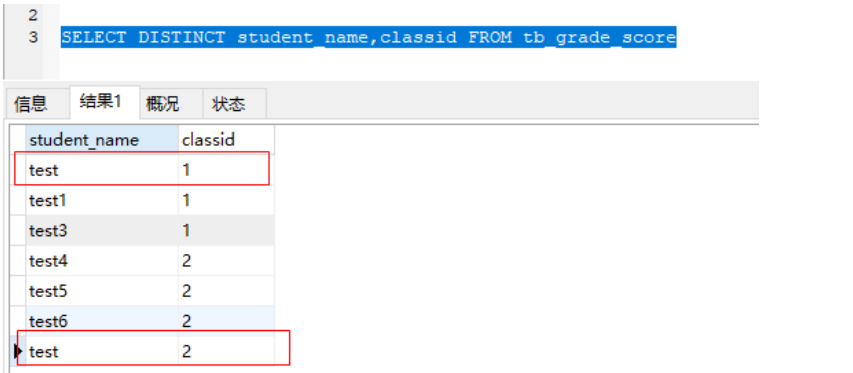
查询去掉重复数据
distinct去掉重复数据
作用于一个字段时,对一个字段去重,作用于多个字段时,要这些字段完全相同才能去重。
group by + count + min查询重复数据

WHERE IN
后面可以是一串选项:
select * from table where uname in('aaa','bbb','ccc','ddd','eee','ffff');
也可以是一个语句:
select * from table where unamein(select uname from user);
WHERE LIKE
SELECT device_id,age,university
FROM user_profile
WHERE university LIKE '%北京%';
EXPLAIN效率查看
mysql> DESC pixel_dot_count;
+----------+----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+----------+------+-----+---------+----------------+
| id | bigint | NO | PRI | NULL | auto_increment |
| str_date | char(16) | NO | MUL | NULL | |
| bang_id | char(10) | NO | MUL | NULL | |
| count | int | NO | | NULL | |
+----------+----------+------+-----+---------+----------------+
4 rows in set (0.03 sec)
MUL是普通索引,因为被索引的数据列包含重复的数据。UNI是唯一索引,插入时会判断这个字段是否已经出现过,如果出现了,就拒绝插入。
唯一索引和普通索引都是B+树。
索引列直接=的情况:

select_type:SIMPLE是简单查询,不使用UNION或子查询
type: 使用了哪种索引:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
system:系统表,少量数据,往往不需要进行磁盘 IO const:常量连接 eq_ref:主键索引 (primary key) 或者非空唯一索引 (unique not null) 等值扫描 ref:非主键非唯一索引等值扫描 range:范围扫描 index:索引树扫描 ALL:全表扫描 (full table scan)possible_keys:可能使用的索引key
key:实际使用的索引
ref:使用哪个列或者常数与key一起从表中选择行
rows: mysql认为它执行查询必须检查的行数。
索引like前后通配符情况(全表查询):

前面可以用索引的情况:

一些函数的使用
找最大gpa然后保留一位小数:
SELECT ROUND(MAX(gpa),1) FROM user_profile WHERE university="复旦大学";
查找男生人数和平均GPA:
SELECT COUNT(id),AVG(gpa) FROM user_profile WHERE gender="male";
分组
GROUP BY
现在运营想要对每个学校不同性别的用户活跃情况和发帖数量进行分析,请分别计算出每个学校每种性别的用户数、30天内平均活跃天数和平均发帖数量。
SELECT gender,university,COUNT(id) AS user_num,
AVG(active_days_within_30) AS avg_active_day,
AVG(question_cnt) AS avg_question_cnt
FROM user_profile
GROUP BY university,gender;
分组过滤
现在运营想查看每个学校用户的平均发贴和回帖情况,寻找低活跃度学校进行重点运营,请取出平均发贴数低于5的学校或平均回帖数小于20的学校。
要使用having:
SELECT university,
ROUND(AVG(question_cnt),3) AS avg_question_cnt,
ROUND(AVG(answer_cnt),3) AS avg_answer_cnt
FROM user_profile
GROUP BY university
HAVING avg_question_cnt<5 OR avg_answer_cnt<20;
或者:
SELECT * FROM
(SELECT university,
ROUND(AVG(question_cnt),3) AS avg_question_cnt,
ROUND(AVG(answer_cnt),3) AS avg_answer_cnt
FROM user_profile
GROUP BY university) AS tmp
WHERE avg_question_cnt<5 OR avg_answer_cnt<20;
分组排序
SELECT university,AVG(question_cnt) AS avg_question_cnt
FROM user_profile
GROUP BY university
ORDER BY avg_question_cnt;
子查询
SELECT device_id,question_id,result FROM question_practice_detail
WHERE device_id IN
(
SELECT device_id
FROM user_profile
WHERE university="浙江大学"
);
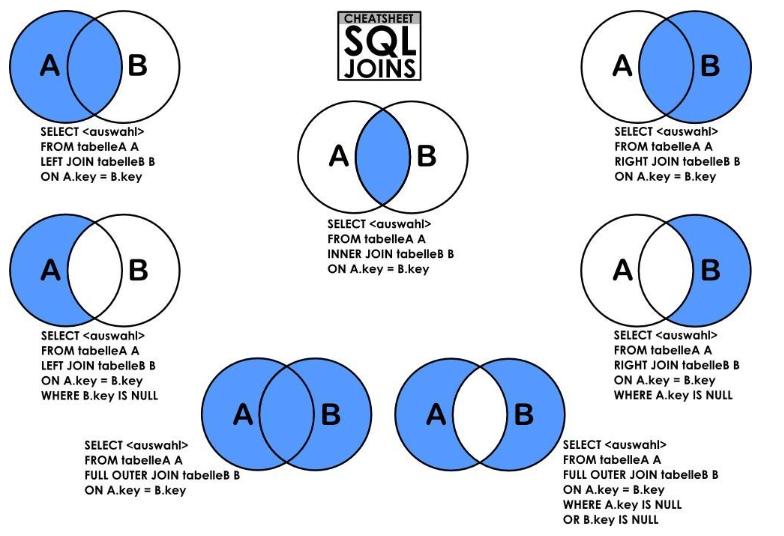
INNER JOIN

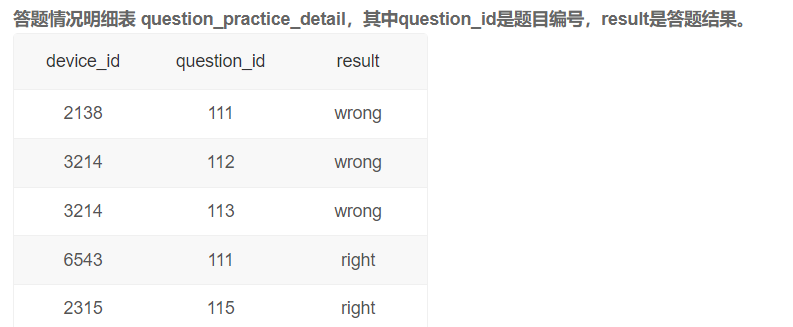
# 写SQL查找每个学校用户的平均答题数目(说明:某学校
# 用户平均答题数量计算方式为该学校用户答题总次数除以答过题的不同用户个数)
SELECT university,
COUNT(q.question_id)/COUNT(DISTINCT(u.device_id)) AS avg_answer_cnt
FROM user_profile AS u
INNER JOIN question_practice_detail AS q
ON u.device_id = q.device_id
GROUP BY university
ORDER BY university;
另一个例子:
# 运营想要查看参加了答题的山东
# 大学的用户在不同难度下的平均答题题目数,请取出相应数据
SELECT a.university,c.difficult_level,COUNT(b.question_id)/COUNT(DISTINCT(a.device_id))
FROM user_profile a,question_practice_detail b,question_detail c
WHERE a.device_id=b.device_id AND b.question_id=c.question_id
GROUP BY a.university,c.difficult_level
HAVING a.university="山东大学";
多表逗号连接并用where 条件做连接条件, 等价于 inner join 内连接
多个表做连接关联是, 数据量小的表form关键字放前面,数据量越大的表越靠后, where条件的表顺序也是如此。
小表驱动大表类似于循环嵌套:
for(int i=0;i<5;i++) {
for(int j=0;j<10000;j++) {
}
}
i只查询了5次,但是调换过来的话:
for(int j=0;j<10000;j++) {
for(int i=0;i<5;i++) {
}
}
i查询了50000次。